Benchmarks¶
Here are the result of a benchmark of multiple neighbor list implementations. The benchmark runs on multiple super-cell of diamond carbon, up to 30’000 atoms, with multiple cutoffs, and using either CPU or CUDA hardware.
The results below are for an AMD 3955WX CPU and an NVIDIA 4070 Ti SUPER GPU; if you want to run it on your own system, the corresponding script is in vesin’s GitHub repository.
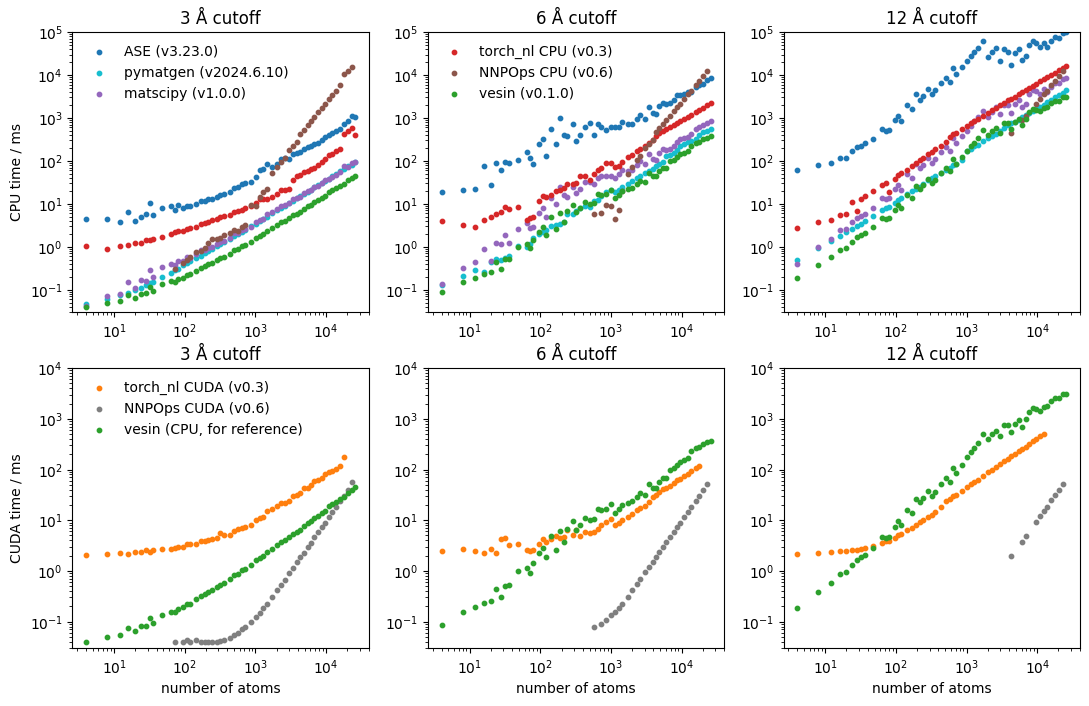
Speed comparison between multiple neighbor list implementations: vesin, ase, matscipy, pymatgen, torch_nl, and NNPOps.¶
Missing points indicate that a specific code could not run the calculation (for example, NNPOps requires the cell to be twice the cutoff in size, and can’t run with large cutoffs and small cells).